Hace varios meses descubrí casualmente que una web española había plagiado uno de mis artículos (ver Cómo ganar con AdSense mediante artículos ajenos, Y el plagio continua…, hilo similar en meneame). Luego de enviar un email a la ‘responsable’ de la web, mi artículo fue retirado y copiado en otra web. Pero la bien conocida señora creo a su manera (nicks, emails, IPs falsos) una gran polémica en los comentarios de mi blog para evitar el desprestigio de su red de proyectos de plagio.
Casualmente (ya que esa web esta baneada de mis favoritos), hace unas semanas encontré nuevamente en Google un enlace a la página que había sido retirada meses atrás, y para mi sorpresa estaba mejor posicionada que mi propio artículo para varias frases relacionadas al tema.
Nuevamente envié un email a la mencionada señora para que retirase mis artículos de sus webs, pero esta vez ni se digno en contestar.
Después de consultar a algunos amigos abogados en España, me informaron que las leyes españolas actualmente no pueden hacer mucho en este tipo de situaciones. Por el contrario, por ejemplo las leyes alemanas sobre temas de Internet y de derechos de autoría de contenidos en Internet, ya estas más avanzadas.
Con esta situación, me puse a pensar de cual sería la mejor solución para evitar este tipo plagio y la respuesta fue rápida: Evitar que este tipo de redes y webs obtengan tráfico. Si es que estas páginas no se pueden posicionar bien en los buscadores, entonces el negocio generado por AdSense con artículos copiados, ya no será tan rentable y estas personas pronto perderán el interés de hacerse de la propiedad ajena.
Con esta motivación, comencé un experimento: Posicionar mi artículo! Con un poco de trabajo SEO conseguí fácilmente obtener mejores posiciones que el articulo falso en unas poca semanas.
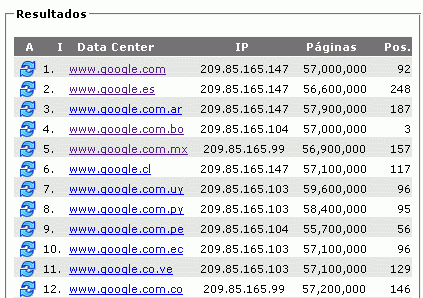
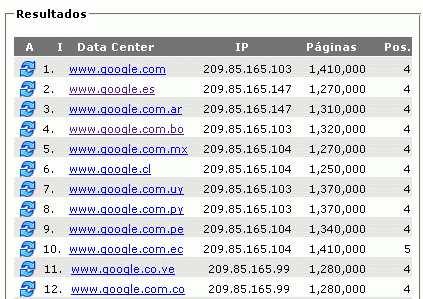
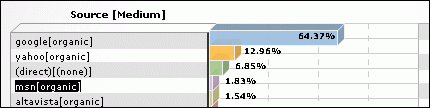
Ahora, mi artículo aparece en las primeras búsquedas para diferentes frases y ha desplazado a la página plagiadora, como lo demuestran estas imágenes:
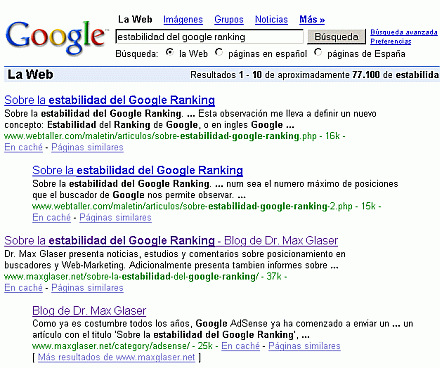
Resultados en el buscador de Google del 28 de Enero de 2007
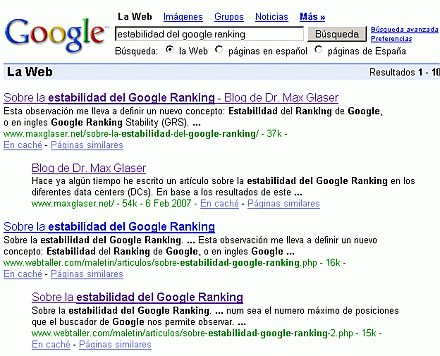
Resultados en el buscador de Google del 07de Febrero de 2007
Y aunque este ejemplo solo es una pequeña prueba de como combatir este tipo de webs, si todos los damnificados logran posicionar sus artículos por encima de los plagiados, los usuarios que buscan información en los motores de búsqueda, siempre encontrarán primero al artículo original. Y por consecuencia, esto causará la caída dramática del trafico de estas webs.
Y para finalizar algunos consejos más para evitar el auge de las redes de webs plagiadoras.
- No enlazar naturalmente a ninguna de las páginas de estas webs
- No realizar intercambio de enlaces
- Divulgar en foros, blog, y otros medios de comunicación el modo de trabajo de estas webs y siempre mencionar que el fin de este modelo es simplemente conseguir ganancias con los avisos contextuales como AdSense en contenidos robados.
Espero que todos los afectados se puedan unir para luchar contra este tipo de plagio.